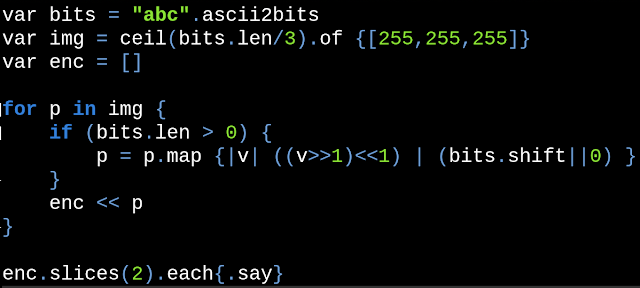
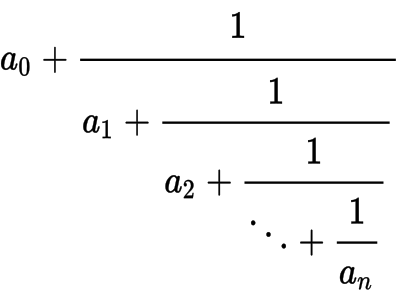
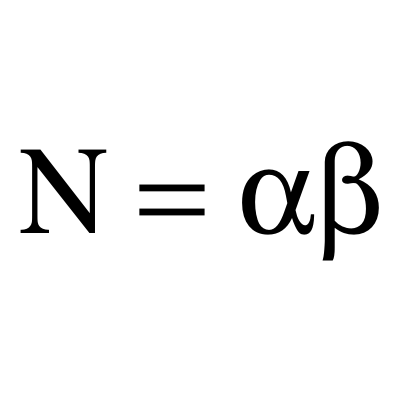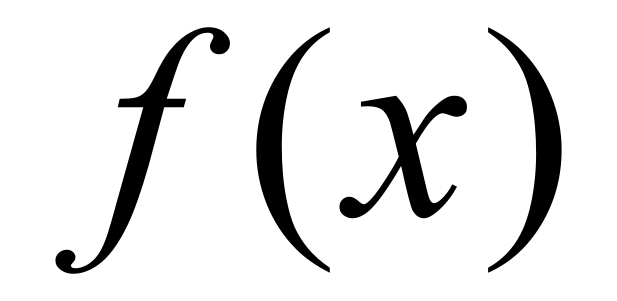RSA is a practical public-key cryptographic algorithm, which is widely used on modern computers to communicate securely over large distances. The acronym of the algorithm stands for Ron Rivest , Adi Shamir and Leonard Adleman , which first published the algorithm in 1978. # Algorithm overview Choose `p` and `q` as distinct prime numbers Compute `n` as `n = p*q` Compute `\phi(n)` as `\phi(n) = (p-1) * (q-1)` Choose `e` such that `1 < e < \phi(n)` and `e` and `\phi(n)` are coprime Compute the value of `d` as `d ≡ e^(-1) mod \phi(n)` Public key is `(e, n)` Private key is `(d, n)` The encryption of `m` as `c`, is `c ≡ m^e mod n` The decryption of `c` as `m`, is `m ≡ c^d mod n` # Generating `p` and `q` In order to generate a public and a private key, the algorithm requires two distinct prime numbers `p` and `q`, which are randomly chosen and should have, roughly, the same number of bits. By today standards, it is recommended that each prime number to have a